In our last post, we extract @realDonalTrump and @JustinTrudeau tweets, clean up the texts, and generate word clouds. In this article, we will build a Latent Dirichlet Allocation (LDA) model to study the topics of the hundreds of tweets posted by the two world leaders.
Topic Modeling
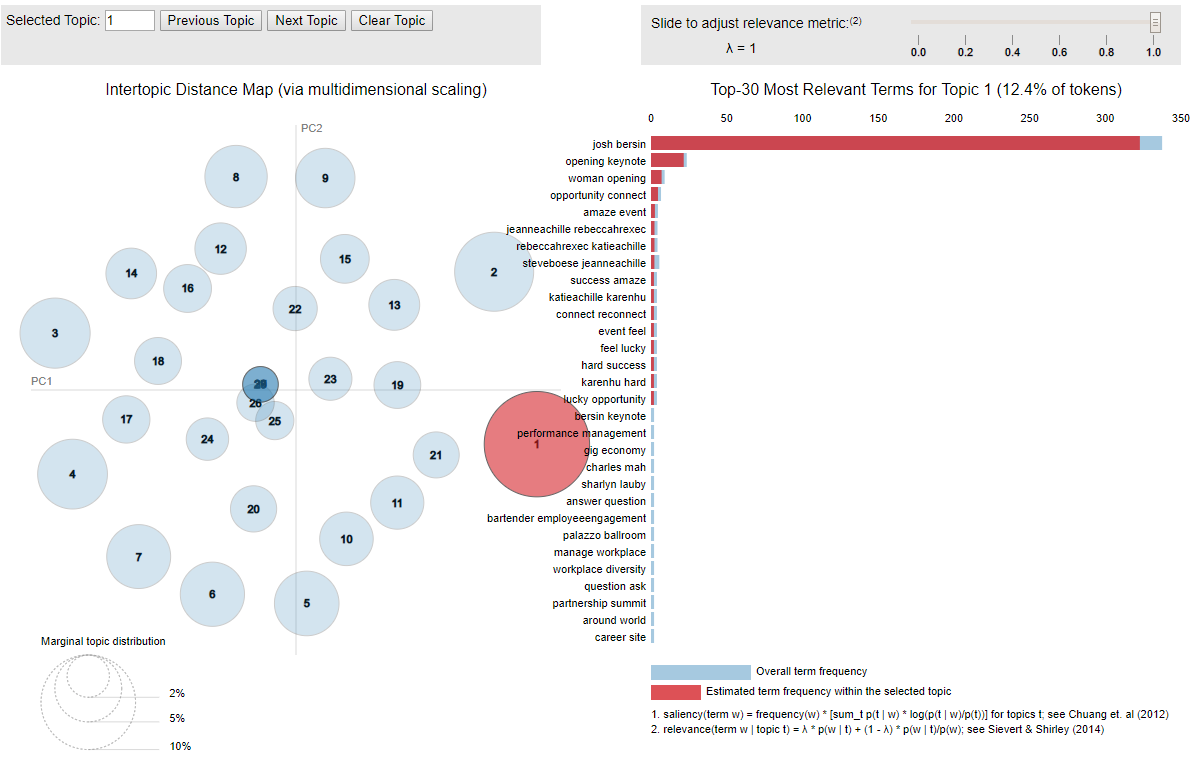
Topic modeling is an unsupervised machine learning technique which is widely used for discovering abstract topics of a collection of documents. It considers each document to be represented by several topics and each topic to be represented by a set of words that frequently appear together. For example, with a cluster of cloud, rain, wind, we can tell that the associated topic likely related to weather.