In our last post, we extract #HRTechConf tweets, clean up the texts, and generate a word cloud that highlights some of the buzzwords from the conference. But, what are the tweets talking about? Without reviewing each of the 7,000 tweets, how could we find out the popular topics? Let’s explore and see if tweet topics could be auto detected by developing a Latent Dirichlet Allocation (LDA) model.
Feature Extraction
Tweets or any text must be converted to a vector of numbers – the dictionary that describes the occurrence of words in the text (or corpus). The technique we use is called Bag of Words, a simple method of extracting text features. Here are the steps.
Bag of Words (Bigrams)
Count bigrams
A bigram is a sequence of two words e.g. machine learning, talent acquisition. Often, a bag-of-bigrams is more powerful and produce more meaningful insights than a bag-of-words (single word, or unigram).
Build dictionary
We build the dictionary (or vocabulary) of the tweets in which all the unique bigrams of the tweets are given IDs and their frequency counts are also captured. We use Gensim library for building the dictionary.
We exclude all the tokens from the dictionary which have occurred in less than 10 tweets, so that we only deal with most representative words. Also bigrams that have occurred in more than 50% of the tweets are also removed e.g. near future, next year.
Here is the Python code:
from gensim import corpora
tweets_dict = corpora.Dictionary(token_tweets)
tweets_dict.filter_extremes(no_below=10, no_above=0.5)Rebuild corpus based on the dictionary
Now, using the dictionary above, we generate a word count vector for each tweet, which consists of the frequencies of all the words in the vocabulary for that particular tweet. Most of them are zero’s as a tweet does not have all the words of the dictionary.
bow_corpus = [tweets_dict.doc2bow(doc) for doc in token_tweets] TF-IDF
Bag of Words is based on the principle that a document is represented by the words that occur most frequently, i.e. words with high “term frequency” (TF). A problem with this approach is that highly frequent words start to dominate in the document, but may not be representative to the model as less-frequent words.
One way to fix this is to measure how unique (or how infrequent) a word is across all documents (or tweets), which is called the “inverse document frequency” or IDF. By introducing IDF, frequent words that are also frequent across all documents get penalized with less weight.
In TF-IDF, we calculate TF x IDF as the weight for each word in the dictionary, representing how frequent this word is in the tweet multiplied by how unique the word is across all tweets. The TF-IDF weight highlights the words that are distinct (relevant information) in a tweet.
from gensim import models
tfidf = models.TfidfModel(bow_corpus)
tfidf_corpus = tfidf[bow_corpus]Topic Modeling Via LDA
Now we are ready to train our LDA model to learn topics from the tweets.
LDA, an unsupervised machine learning algorithm, is a generative statistical model that takes documents as input and finds topics as output. Each document is considered as a mixture of a number of topics, and each topic is determined by frequency of the words (or word distribution). LDA is a popular probabilistic topic modeling algorithm. Here is an introduction to Latent Dirichlet Allocation.
We use Gensim library to train our LDA model over 7,000 tweets. Some model hyper-parameters to tune:
- Number of topics: Each topic is a set of keywords, each contributing a certain weight (i.e. importance) to the topic. Too few topics result in non-cohesive topics, containing heterogeneous set of words, which are difficult to distinguish. Too many topics do not provide any semantic meaning of any topic. Given that it was a big event and tweets covered several days, the number of topics of all tweets is likely to be high. We set 30 as the number of topics. We also tried 10, 20 and 50, and none showed better result than 30.
- Alpha (Document-Topic Density): The lower alpha is, the more likely that a tweet may contain mixture of just a few of the topics. Default is
1.0/NUM_TOPICSWe used0.001as each tweet is quite short and is very likely to only have one topic.
- Eta (Word-Topic Density): The lower eta is, the more likely that a topic may contain a mixture of just a few of the words. Default is
1.0/NUM_TOPICSWe used the default.
- Number of passes: Number of training passes/iterations over all tweets. We set it to be 50. We tried bigger numbers and they did not produce better results.
from gensim import models
NUM_TOPICS = 30
NUM_PASSES = 50
ALPHA = 0.001
ETA = 'auto'
# Train LDA model
lda_model = models.ldamodel.LdaModel(corpus=tfidf_corpus,
num_topics=NUM_TOPICS,
id2word=tweets_dict,
passes=NUM_PASSES,
alpha=ALPHA,
eta=ETA,
random_state=49)Below are some example topics. The higher the numbers are, the bigger weights (importance) they contribute to the topic.
Topic: 20 Words: 0.823*"josh bersin" + 0.055*"opening keynote" + 0.018*"woman opening" + 0.012*"opportunity connect" + 0.007*"amaze event" + 0.006*"rebeccahrexec katieachille" + 0.006*"jeanneachille rebeccahrexec" + 0.006*"steveboese jeanneachille" + 0.005*"event feel" + 0.005*"lucky opportunity"
It seems this topic is about “josh bersin” addressing “opening keynote” and “woman opening”. After checking HR Tech Conf website, we can confirm Josh Bersin is a keynote speaker and Women in HR Tech opening happens at the same venue. Here is an example tweet:
Checking in from @Josh_Bersin’s opening keynote at #HRTechConf today! Our team loved hearing Josh share his insights on how technology is shaping and creating new opportunities for HR. pic.twitter.com/ku27LKzmcb
Topic: 3
Words: 0.259*"kronos ceo" + 0.059*"rule follow" + 0.041*"kronos highly" + 0.041*"surprisingly simple" + 0.041*"simple rule" + 0.041*"reveals surprisingly" + 0.041*"replicate success" + 0.041*"workinspired kronos" + 0.041*"follow replicate" + 0.041*"culture reveals"
It seems this topic is about Kronos CEO reveals some surprisingly simple rule (of culture? for success?) Here is a tweet:
#hrconfes RT KronosInc: In #WorkInspired, Kronos CEO Aron Ain takes you inside Kronos highly admired culture — and reveals the surprisingly simple rules you can follow to start replicating that success. #HRTechConf
Topic: 7 Words: 0.187*"marcus buckingham" + 0.177*"book signing" + 0.138*"free copy" + 0.124*"nine lie" + 0.079*"present lie" + 0.079*"buckingham present" + 0.001*"peopledoc inc" + 0.001*"drive engagement" + 0.001*"around world" + 0.001*"answer question"
It seems this topic is about Marcus Buckingham having book signing and giving free copies (of Nine Lies? Book name maybe) Here is a tweet:
#hrtechconf book signing with Marcus Buckingham #FreeThinkingCoalition #9liesaboutwork https://www.instagram.com/p/B3KhdHWlRgRIFxreqnoIXDaZNthcdr-_TJ8aeo0/?igshid=19rvtzygznze1 …
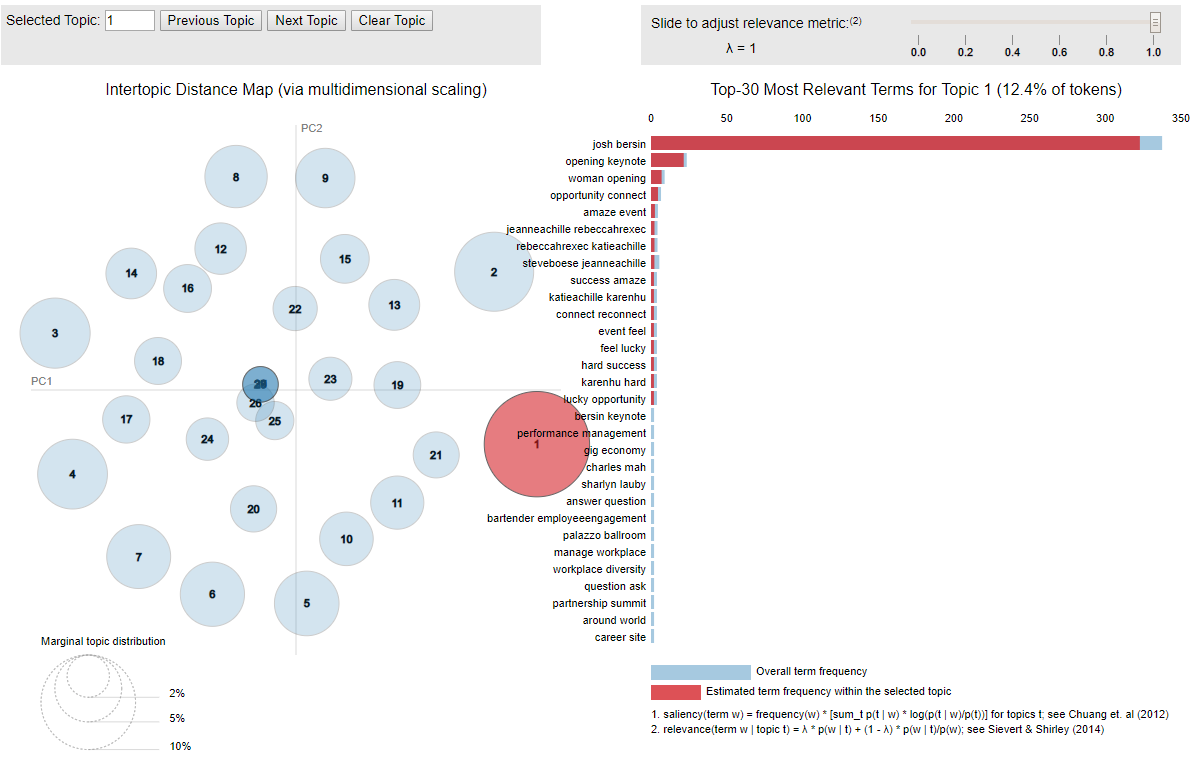
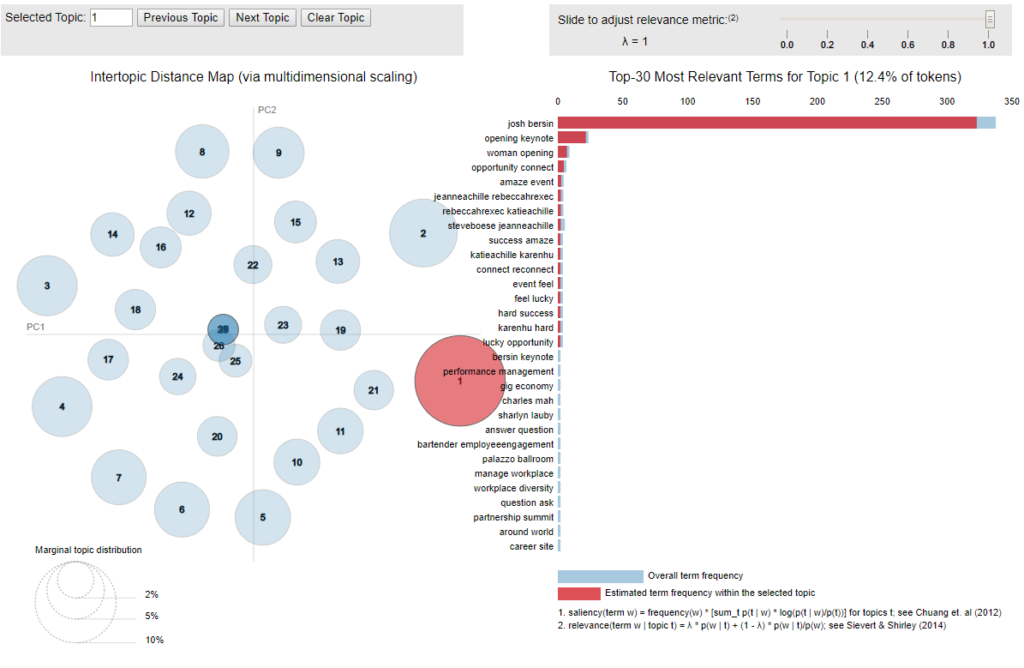
Topic Visualization
To make it more interesting, we use pyLDAvis, an interactive LDA visualization package, to plot all generated topics and their keywords. pyLDAvis calculates semantic distance between topics and projects topics on a 2D plane.
import pyLDAvis.gensim
lda_data = pyLDAvis.gensim.prepare(lda_model, corpus, dict, mds='mmds')
pyLDAvis.display(lda_data)Here is the link to the interactive page.
Each bubble on the left represents a topic. The size of the bubble represents prevalence of the topic. The distance between the bubbles reflects the similarity between topics. The closer the two circles are, the more similar the topics are.
A good topic model should have some dominant bigger bubbles, with smaller ones scattered on the plane. If a plot has many overlapping small circles, typically it is a sign of having too many topics.
On the right hand side, it shows the top 30 most important bigrams of the topic. When hove over a bubble, it will update the list of words on the right. Also, if you select a work from the list, it will highlight the circle(s) that the selected word appears.
Closing Notes
We scraped #HRTechConf tweets, generated a word cloud to show the buzzwords, and built a LDA model to lean the topics of the tweets.
LDA is difficult to train and results need human interpretation. However, it is very powerful and yet intuitive. Our experiment shows that the words of the learned topics are not perfectly similar or coherent but are definitely relevant to the topic.
Future works to improve the LDA results:
- Optimize hyper-parameters using Grid Search
- Formally determine the best number of topics for best modeling performance
All codes can be found on GitHub.
Happy Machine Learning!