
Year 2020 is not off to a good start. The ongoing Coronavirus outbreak that originated in Wuhan, China has infected thousands of people worldwide and killed hundreds. Numbers are still rising everyday. With all the quarantine controls and vaccine development, hope this global epidemic will be soon under control.
When we are facing such a global challenge, we take our emotions and concerns to social media and share Coronavirus news with others. Since the outbreak, each day there are hundreds of thousands of tweets about Coronavirus. I decided to run analyses on Twitter feeds and see if I could generate some highlights.
Similar to this previous article, I use Python 3.6 and the following packages:
- TwitterScraper, a Python script to scrape for tweets
- NLTK (Natural Language Toolkit), a NLP package for text processing, e.g. stop words, punctuation, tokenization, lemmatization, etc.
- Gensim, “generate similar”, a popular NLP package for topic modeling
- Latent Dirichlet Allocation (LDA), a generative, probabilistic model for topic clustering/modeling
- pyLDAvis, an interactive LDA visualization package, designed to help interpret topics in a topic model that is trained on a corpus of text data
The entire work takes about 20 minutes.
Data Gathering
Twitter feeds on February 1, 2020 with keyword “coronavirus” are extracted. Although hundreds of thousands “coronavirus” tweets are charged everyday, I stopped scraping after gathered 14,400 tweets which should be a good sample size for providing insights.
Word Count and Word Cloud
After same pre-processing steps in this previous article, first I generated a word cloud using uni-grams i.e single word.

It shows keywords like China, Wuhan, virus, case, etc, but does not offer much insight. I then tried bi-grams i.e. two words.

Some more interesting words are standing out: New York, eighth case, confirm Massachusetts, etc. Here is the actual word count:
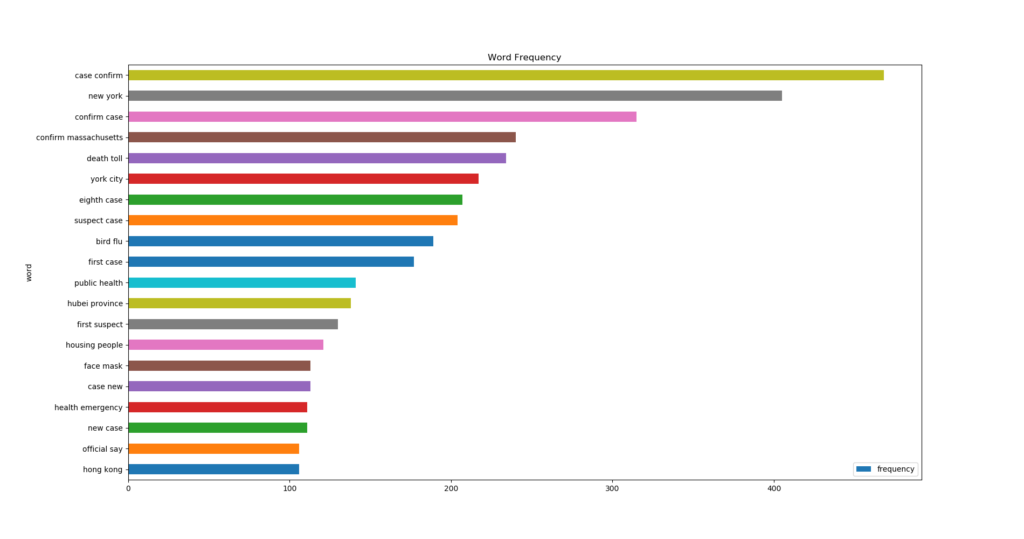
What is the word cloud trying to tell us? What are the stories people were twittering about? Let’s see if topic clustering could tell us the answer.
Topic Clustering
Again, following the same steps in this previous article, I applied LDA algorithm to learn the topics in the extracted tweets. An interactive graph is generated to show different topics with their associated keywords.
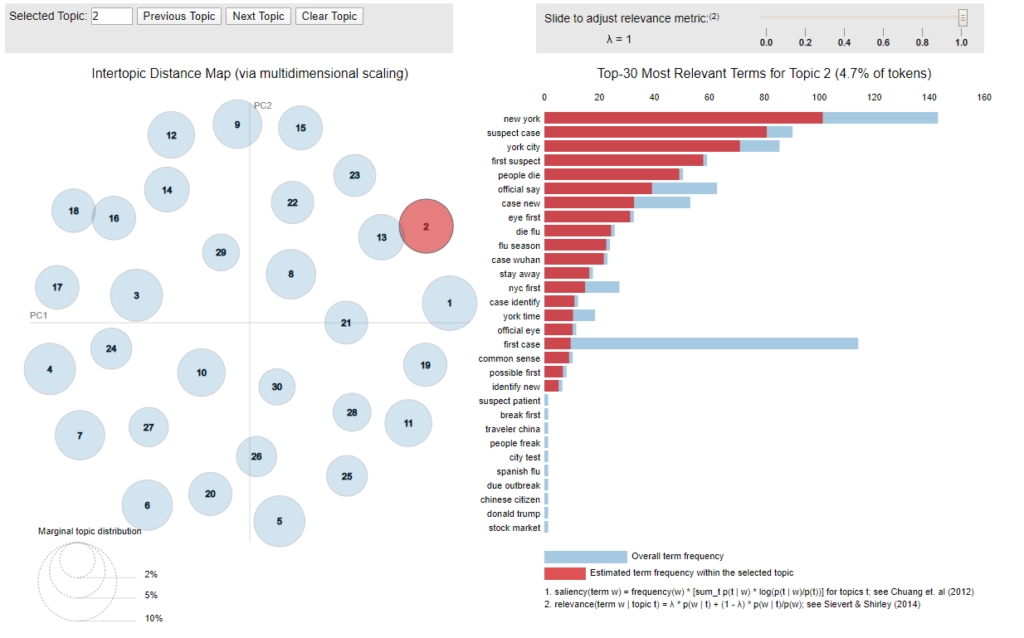
If you go through some of the topics, you will see New York, suspect case, first suspect under one topic (That is correct – New York had their first suspect coronavirus case reported on that day). Keywords in another topic, United States, Boston man, case Massachusetts, eighth case (That is correct – a Boston man was confirmed to be the eighth coronavirus case in Massachusetts).
If you are like me, no time to read social feeds, this would be a quick way to catch up on the latest #coronavirus updates. I sincere hope this epidemic will come to an end soon.