HR Technology Conference and Expo, world’s leading and largest conference for HR and IT professionals, just took place in Las Vegas, from Oct 1 – 4, 2019. An incredibly amount of HR technology topics were covered at the conference. Unfortunately not everyone could be there, including myself. Is it possible to tell what the buzzwords and topics are without being there? The answer is YES! I dig into Twitter for some quick insights.
I scrape tweets with #HRTechConf, and build Latent Dirichlet Allocation (LDA) model for auto detecting and interpreting topics in the tweets. Here is my pipeline:
- Data gathering – twitter scrape
- Data pre-processing
- Generating word cloud
- Train LDA model
- Visualizing topics
I use Python 3.6 and the following packages:
- TwitterScraper, a Python script to scrape for tweets
- NLTK (Natural Language Toolkit), a NLP package for text processing, e.g. stop words, punctuation, tokenization, lemmatization, etc.
- Gensim, “generate similar”, a popular NLP package for topic modeling
- Latent Dirichlet Allocation (LDA), a generative, probabilistic model for topic clustering/modeling
- pyLDAvis, an interactive LDA visualization package, designed to help interpret topics in a topic model that is trained on a corpus of text data
Data Gathering
It is always challenging to scrape Twitter using its own API. One of the biggest disadvantages is that it only allows searching tweets published in the past 7 days. This is a major bottleneck for anyone looking for older past data to make a model from. Luckily, with TwitterScraper there is no such limitation.
I scrape tweets that have a keyword ‘HRTechConf’ from 09/26/2019 to 10/06/2019. In 10 days, there are 7,274 tweets, with most tweets charged from Oct 1 – 3 (first 3 days of the conference).
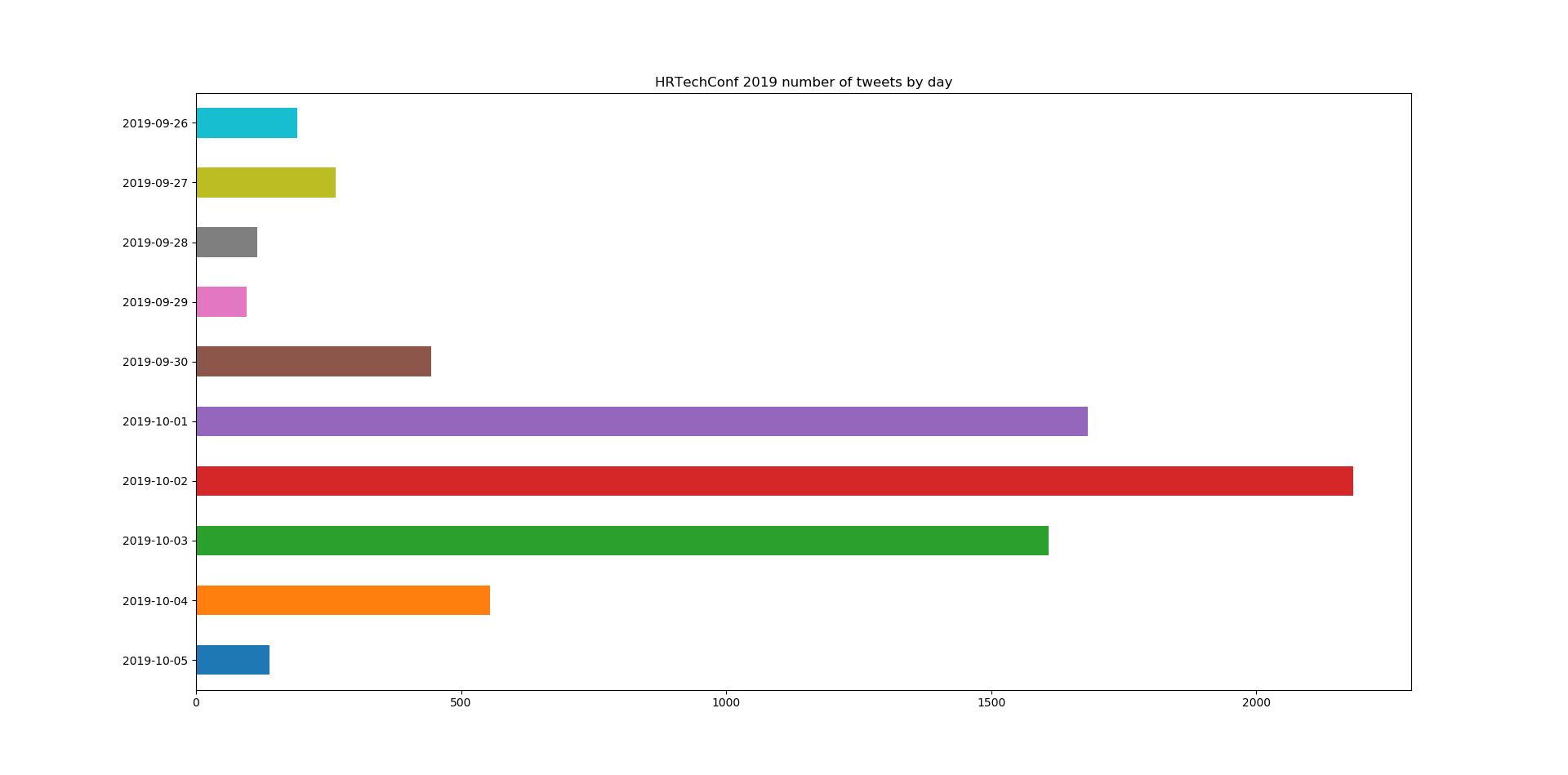
Let’s take a look at some tweets.
Charles Mah of @Workday @ #HRTechConf highlights the essential role of change management in transforming your team and your tech stack. It’s often underestimated and under-resourced but is critical to your success as a TA leader.
Join us and @Insperity for “Employee Metrics Matter, Discover #PeopleAnalytics” session from 2:15-3:15 pm today and you will be entered to win 2 roundtrip tickets to anywhere in the continental U.S.! #HRTechConf #VisierAtHRTech https://buff.ly/32CN2wN pic.twitter.com/b3PRF36gTA
@josh_bersin talks about massive growth in #talentacquisition. @jobvite thinks the space is crowded and fragmented with point solutions. check out our TA tech infographic. https://bit.ly/2nQdmVq #HRTechConf
Data Pre-processing
Pre-processing is a critical task in text mining. Before we can analyze for any insight, the following pre-processing pipeline is applied to transform tweets into a form that is analyzable.
- Convert all words to lowercase
- Remove non-alphabet characters
- Remove short word (length less than 3)
- Tokenization: breaking sentences into words
- Part-of-speech (POS) tagging: process of classifying words into their grammatical category, in order to understand their roles in a sentence, e.g. verbs, nouns, adjectives, etc. POS tagging provides grammar context for lemmatization.
- Lemmatization: converting a word to its base form e.g. car, cars and car’s to car
- Remove common English words e.g. a, the, of, etc., and remove common words that add very little value to our analysis, e.g. hrtechconf, much, hr, get, etc.
After pre-processing, the aforementioned three tweets are transformed to:
| 1 | [‘charles’, ‘mah’, ‘workday’, ‘highlight’, ‘essential’, ‘role’, ‘change’, ‘management’, ‘transform’, ‘stack’, ‘often’, ‘underestimated’, ‘resourced’, ‘critical’, ‘success’, ‘leader’] |
| 2 | [‘insperity’, ‘metric’, ‘matter’, ‘discover’, ‘enter’, ’roundtrip’, ‘ticket’, ‘anywhere’, ‘continental’, ‘visierathrtech’, ‘prf’, ‘gta’] |
| 3 | [‘josh’, ‘bersin’, ‘massive’, ‘growth’, ‘talentacquisition’, ‘jobvite’, ‘space’, ‘crowd’, ‘fragment’, ‘point’, ‘solution’, ‘infographic’] |
Word Count and Word Cloud
It is difficult to interpret meaning of a single word. For example, machine could be mechanical machine, machine gun, or machine learning. Instead, I extract bigrams, pairs of consecutive words for word count. Here are the top 20 most frequent phrases in all extracted tweets.
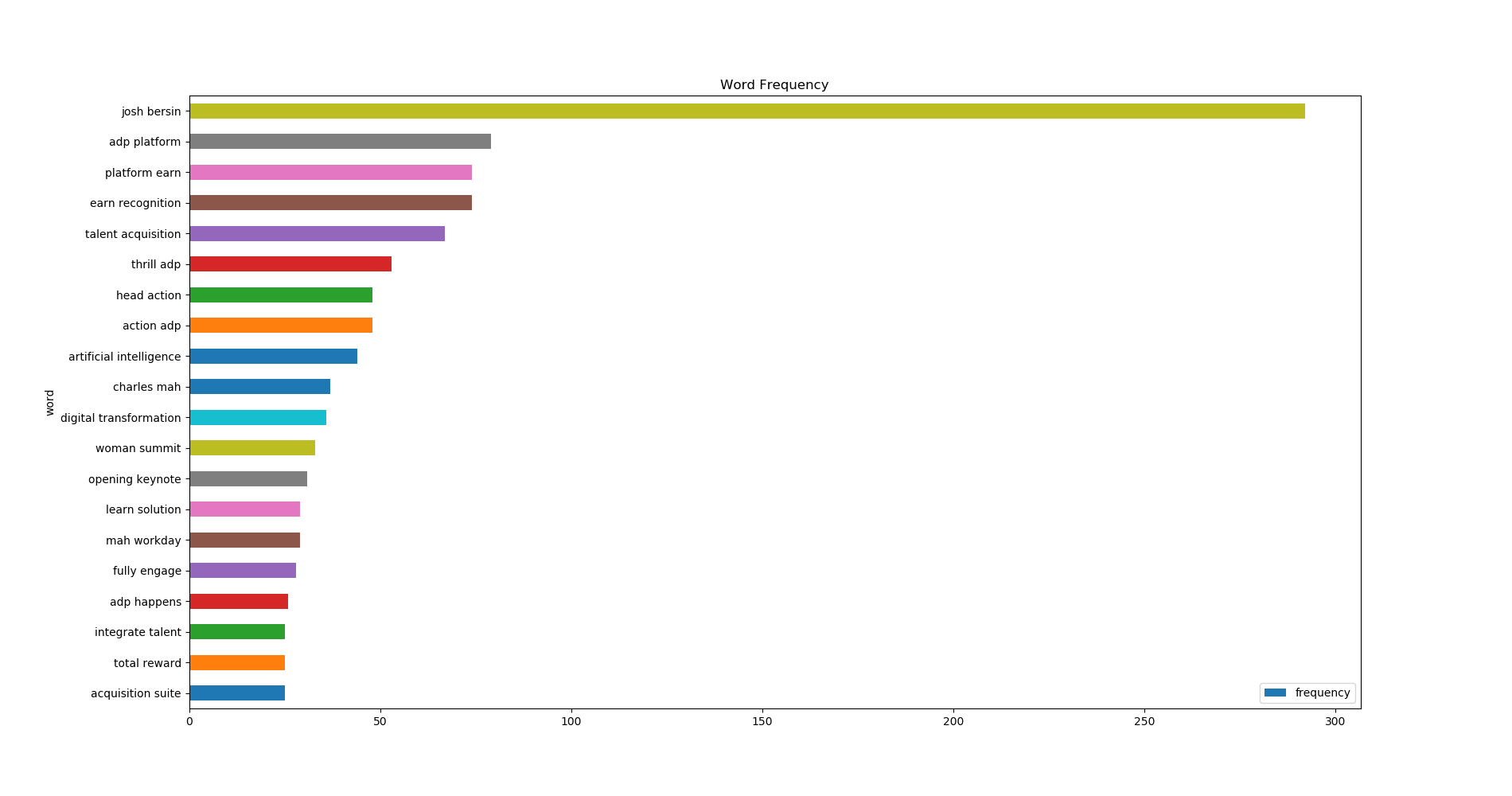
What can we tell from this list?
- “josh bersin” gets most tweeted – Josh Bersin is a keynote speaker.
- ADP has a lot of Twitter coverage “adp platform”, “thrill adp”, “action adp”, “adp happens” – ADP is a Gold Sponsor of the conference and its human capital management (HCM) platform earned some top spotlights at the event.
- “artificial intelligence” appears in many tweets.
- “woman summit” is mentioned many times – This conference is also featuring Women in HR Tech.
Here is the word cloud:

In the next post, I will show how an LDA model is trained to fit the tweet extracts so that some meaningful topics can be formed together.
Happy Machine Learning!