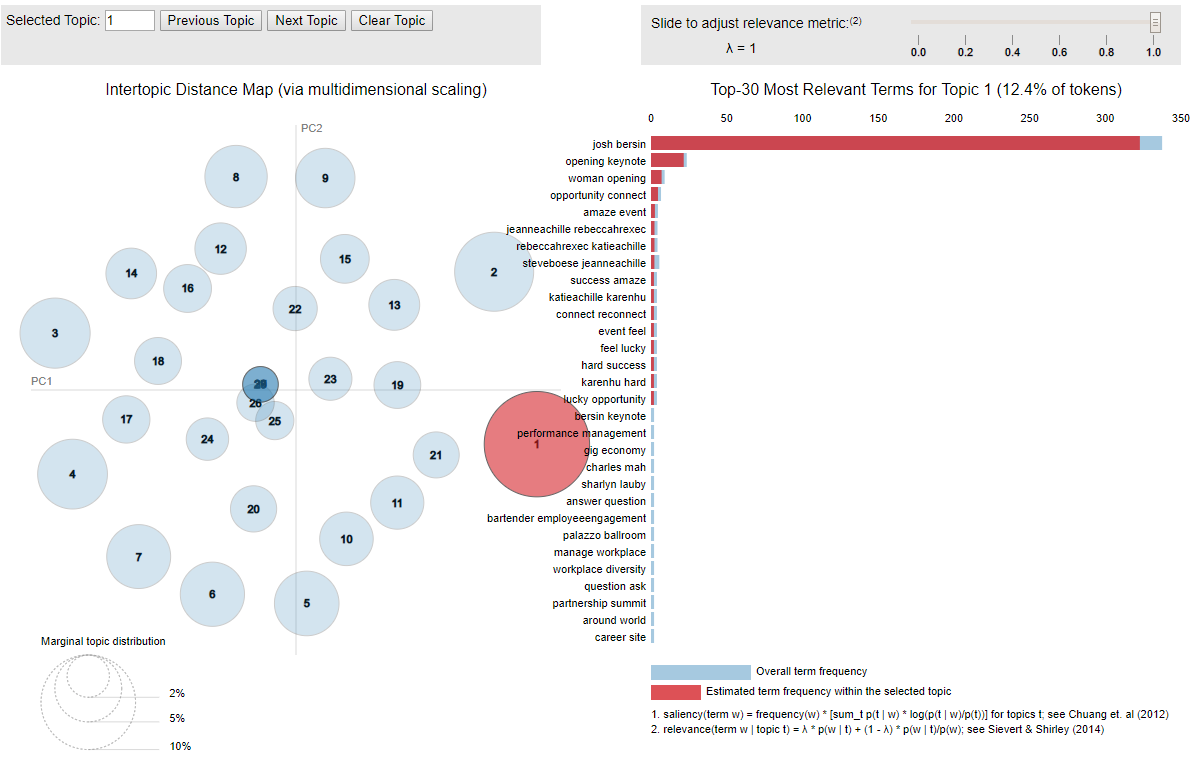
In our last post, we extract #HRTechConf tweets, clean up the texts, and generate a word cloud that highlights some of the buzzwords from the conference. But, what are the tweets talking about? Without reviewing each of the 7,000 tweets, how could we find out the popular topics? Let’s explore and see if tweet topics could be auto detected by developing a Latent Dirichlet Allocation (LDA) model.
Feature Extraction
Tweets or any text must be converted to a vector of numbers – the dictionary that describes the occurrence of words in the text (or corpus). The technique we use is called Bag of Words, a simple method of extracting text features. Here are the steps.
Continue reading “Auto Generated Insights of 2019 HR Tech Conference Twitter – Part 2 (Topic Modeling)”