
Have you applied for loans, grants, or financial assistance programs? Have you dedicated significant time to deciphering legal or contractual documents to understand regulations and rules? Are you looking to streamline the process of reviewing extensive requirement documents? Your solution is here. I have developed an LLM chatbot, supported by RAG, to provide prompt responses to user inquiries based on the content of provided PDF documents.
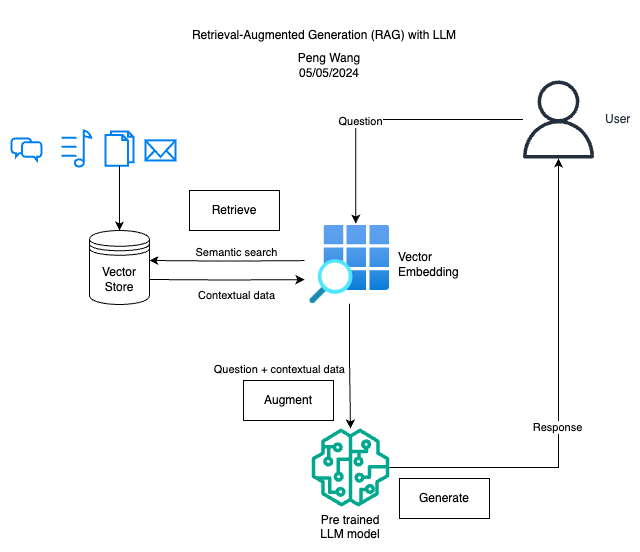
Retrieval Augmented Generation (RAG) involves enhancing Large Language Models (LLMs) with additional information from custom external data sources. This approach improves the LLM’s understanding by providing context from retrieved data or documents, enhancing its ability to respond to user queries with domain-specific knowledge.
- Retrieve: User queries are used to fetch relevant context from an external knowledge source. The queries are embedded into a vector space along with the additional context, allowing for a similarity search. The top k closest data objects from the vector database are then returned.
- Augment: The user query and retrieved additional context are combined into a prompt template.
- Generate: The retrieval-augmented prompt is then input into the LLM for final processing.
In my experiment, I utilized PDF documents as the external knowledge source. Users can ask questions or make queries based on the context provided in these documents. I employed the HuggingFace model sentence-transformers/multi-qa-MiniLM-L6-cos-v1 for vector embedding and the pre-trained LLM model meta-llama/Llama-2-7b-chat-hf for generating the final results.