
According to the U.S. Bureau of Labor Statistics, 4.5 years is the average amount of time employees stay with their company today. It hurts an organization’s financials and morale , considering the amount of time they spend training. Can management learn from the past attrition and manage to reduce turnovers? Answer is yes. We will build some predicative models using the fictional IBM data set which contains 1470 employee attrition records.
This post is part of a series of people analytics experiments I am putting together:
- Job skill match (Recruitment )
- Employee attrition prediction (Employee Management)
- Pay gap by gender, ethnicity, profession (Employee Compensation) FUTURE WORK
- Organizational network analysis (ONA) FUTURE WORK
Python code can be found on my GitHub.
Data visualization
Demographic-related features
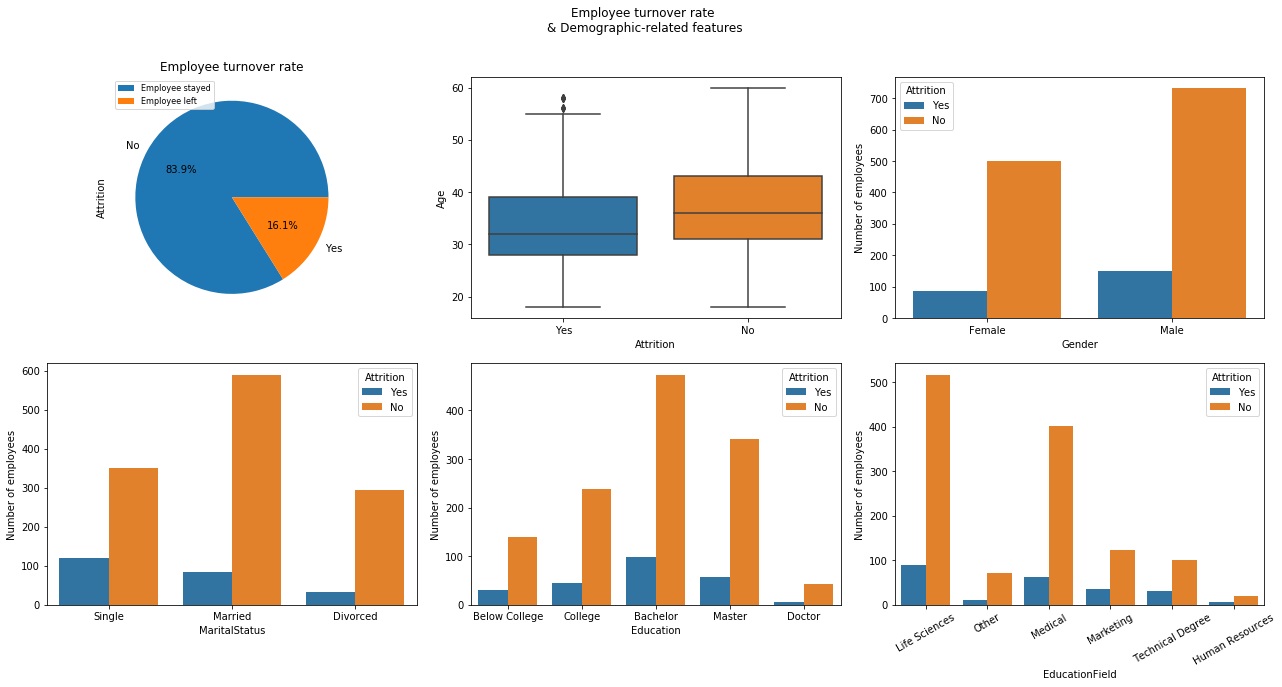
Analysis:
- Turnover rate: 16.1%
- Employees who left have an average age of 33.61, vs 37.56 for those that stay
- Employee who is single has a relatively higher turnover rate
- Employee who has a technical degree is more likely to leave
Work-related features

Analysis:
- Sales department has a higher turnover rate
- Employees with Sales and Lab Technician roles are at a higher risk leaving the org
- The lower job levels, the higher turnovers
- Employees who have longer career years and history with the company tend to stay
Compensation-related features

Analysis:
- Employees with lower monthly income or daily rate are more likely to leave
- Employees who have none stock options are most likely to exit
Employee-satisfaction-related features
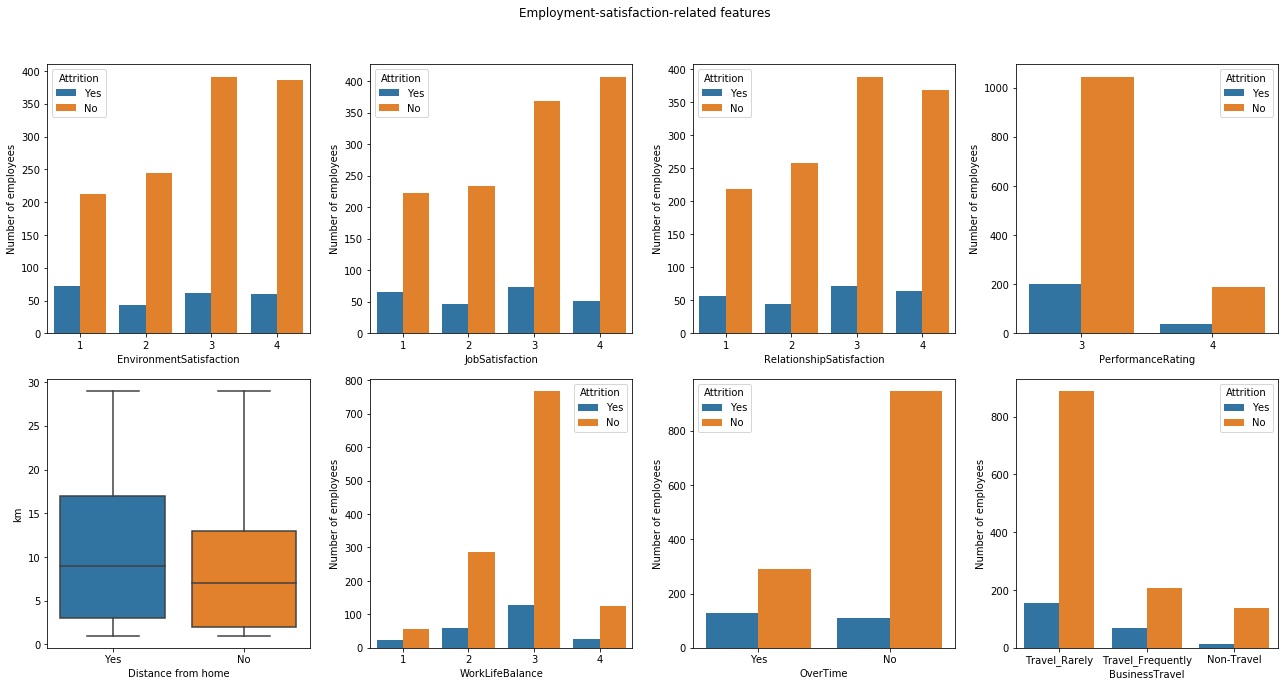
Analysis:
- Employees who are satisfied with their jobs and environment are likely to stay
- Distance from home is a big factor – people who spend more time on commute are likely to exit
- Employees who have a lot of overtimes are at higher risk of leaving
Train and Test Models
1470 attrition records are split to training (1176) and test data (294). Ten-fold validation is used for training.
3 models are built: Decision Tree, Random Forest, XGBoost. Their performances on test data are:
| Model | Accuracy score | Time to run |
| Decision Tree | 0.8333 | 2 sec |
| Random Forest | 0.8707 | 24 sec |
| XGBoost | 0.8844 | 52 sec |
Our data set is highly imbalanced i.e. 84% stay (negative) and 16% left (positive). In general, decision tree does not deal with imbalanced data well because it takes into account the class distribution. It gives the lowest accuracy score in the experiment.
RF and XGBoost, both ensemble learners which train multiple learning algorithms to get better predictive results, are built to better handle imbalanced data set. RF combines many decision trees on various sub-samples of the data set and aggregates on the output of each tree to product a collective prediction. XGBoost is a more recent and more powerful gradient boosting method. It also ensembles many decision trees. Instead of giving Yes and No, it calculates and assigns positive and negative values to each decision tree. Collectively, it averages out incorrect prediction of individual trees and produce a better final result. However, it takes more time to tune XGBoost parameters and train the model. The experiment demonstrates XGBoost has the highest accuracy and much longer run time.
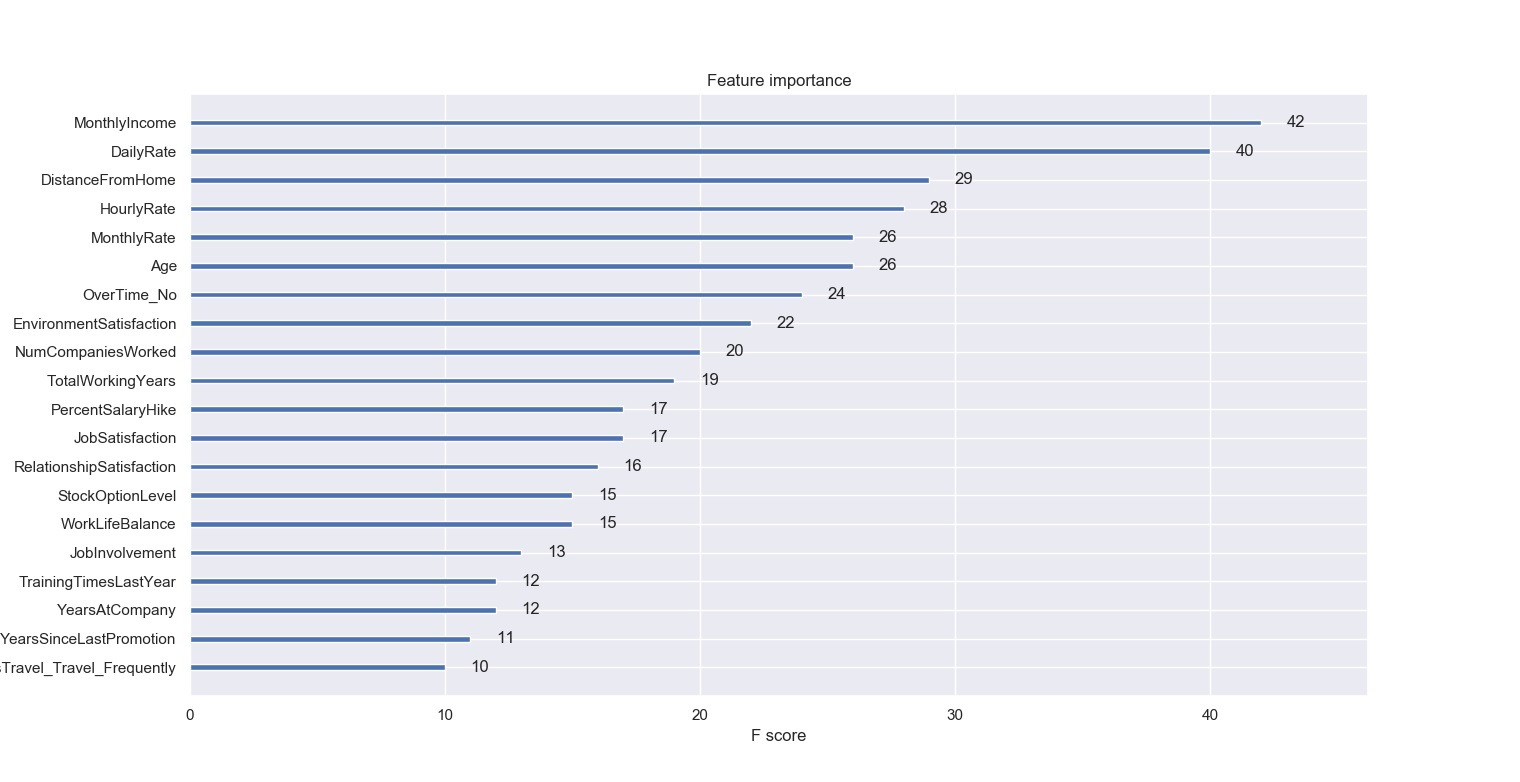
Image below shows feature importance. Monthly Income and Daily Rate have the greatest impact on employee turnover, followed by Distance From Home. These findings are consistent with our analyses above.
Future Work
- As our experiment runs on a fictional data set, all analyses and predictions have no real life meaning. It would be great if it can done using real employee turnover data.
- Try over-sampling/under-sampling techniques with the imbalanced data set
- Add new features by combining different features, e.g. monthly income + age
Again, Python code can be found on my GitHub.
Happy Machine Learning!