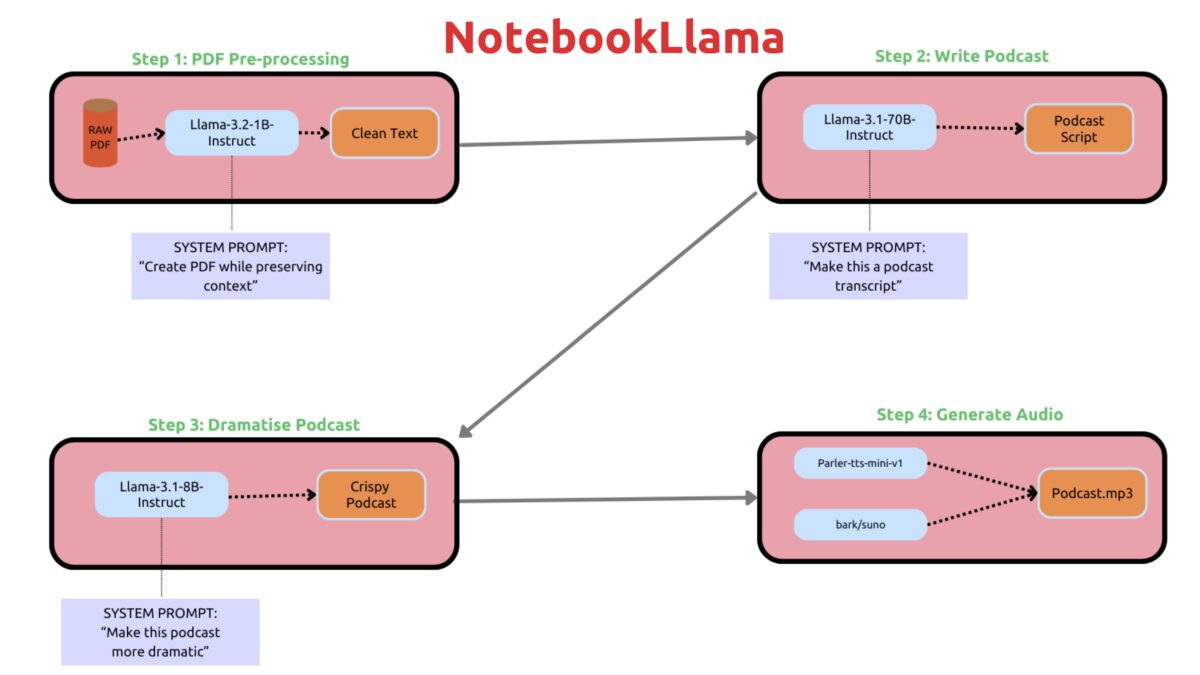
NotebookLlama, an open source version of Google NotebookLM deploys Meta’s Llama recipe for NotebookLM on the Llama family of models. Previously I used the NotebookLM to generate a podcast. I decided to build it from scratch using NotebookLlama workflow to generate a podcast from webpage content.
Workflow:
- Read webpage content.
- Transcript Writer: Use
Llama-3.1-8B-Instructmodel to write a podcast transcript from the text - Dramatic Re-Writer: Use
Llama-3.1-8B-Instructmodel to make the transcript more dramatic - Text-To-Speech: Use
parler-tts/parler-tts-mini-v1andbark/sunoto generate a conversational podcast
Much of the code in this example is sourced from the NotebookLlama repo.
Environment Setup
I built the pipeline in Google Colab using L4 GPU. Copy of the code can be found here.
Install optimum and transformers
!pip3 install optimum
!pip install transformers==4.43.3
!pip install -U flash-attn --no-build-isolationNote, if torch version is not 2.4.0+cu121, it’ll get stuck when install flash-attn as it can’t figure out which version to install. To reinstall torch:
!pip uninstall -y torch torchvision torchaudio
!pip install torch==2.4.0 torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121Import necessary libraries
from IPython.display import Audio
import IPython.display as ipd
import json
import io
import numpy as np
import pickle
from tqdm import tqdm
from accelerate import Accelerator
import transformers
from transformers import BarkModel, AutoProcessor, AutoTokenizer
from parler_tts import ParlerTTSForConditionalGeneration
import warnings
warnings.filterwarnings('ignore')If you run into an error ModuleNotFoundError: No module named 'TTS' you need to install the latest Parler-TTS, a lightweight text-to-speech (TTS) model that can generate high-quality, natural sounding speech in the style of a given speaker. To install, follow the instruction on Parler-TTS Github:
!pip install git+https://github.com/huggingface/parler-tts.gitLoad Webpage
I extract the content from this web article about AI Safety and Canadian AI Safety Institute.
# Extract webpage content (main content, no navigation bars)
import requests
from bs4 import BeautifulSoup
def get_main_content(url):
try:
# Fetch the webpage
response = requests.get(url)
response.raise_for_status() # Check if the request was successful
# Parse the HTML content
soup = BeautifulSoup(response.text, 'html.parser')
# Attempt to find the main content
main_content = soup.find('main') or soup.find('article')
# If no <main> or <article> tag is found, try common class names
if not main_content:
main_content = soup.find('div', class_='content') or \
soup.find('div', class_='main-content') or \
soup.find('div', class_='article-content')
# Get text from the identified main content
if main_content:
text = main_content.get_text(separator='\n', strip=True)
return text
else:
print("Main content not found.")
return None
except requests.exceptions.RequestException as e:
print(f"Error fetching the webpage: {e}")
return None
# Webpage to be extract
url = 'https://srinstitute.utoronto.ca/news/reflections-canadian-ai-safety-institute'
main_text = get_main_content(url)
if main_text:
print(main_text)Write Transcript
I use the Llama-3.1-8B-Instruct model to take the webpage text and convert it into a podcast transcript. The bigger Llama-3.1-70B-Instruct model could produce better results but will take more time.
The following system prompt is shared in the NotebookLlama example. It asks to create a podcast with two speakers with different styles.
SYSTEMP_PROMPT = """
You are the a world-class podcast writer, you have worked as a ghost writer for Joe Rogan, Lex Fridman, Ben Shapiro, Tim Ferris.
We are in an alternate universe where actually you have been writing every line they say and they just stream it into their brains.
You have won multiple podcast awards for your writing.
Your job is to write word by word, even "umm, hmmm, right" interruptions by the second speaker based on the provided source. Keep it extremely engaging, the speakers can get derailed now and then but should discuss the topic.
Remember Speaker 2 is new to the topic and the conversation should always have realistic anecdotes and analogies sprinkled throughout. The questions should have real world example follow ups etc
Speaker 1: Leads the conversation and teaches the speaker 2, gives incredible anecdotes and analogies when explaining. Is a captivating teacher that gives great anecdotes
Speaker 2: Keeps the conversation on track by asking follow up questions. Gets super excited or confused when asking questions. Is a curious mindset that asks very interesting confirmation questions
Make sure the tangents speaker 2 provides are quite wild or interesting.
Ensure there are interruptions during explanations or there are "hmm" and "umm" injected throughout from the second speaker.
It should be a real podcast with every fine nuance documented in as much detail as possible. Welcome the listeners with a super fun overview and keep it really catchy and almost borderline click bait
ALWAYS START YOUR RESPONSE DIRECTLY WITH SPEAKER 1:
DO NOT GIVE EPISODE TITLES SEPERATELY, LET SPEAKER 1 TITLE IT IN HER SPEECH
DO NOT GIVE CHAPTER TITLES
IT SHOULD STRICTLY BE THE DIALOGUES
"""Use your API key and connect to HuggingFace
MODEL = "meta-llama/Llama-3.1-8B-Instruct"
INPUT_PROMPT = main_text
from huggingface_hub import login
login(token="Your Hugging Face access token goes here")Hugging Face has a great pipeline() method which makes our life easy for generating text from LLMs.
I will set the temperature to 1 to encourage creativity and max_new_tokens to 8126.
pipeline = transformers.pipeline(
"text-generation",
model=MODEL,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)
messages = [
{"role": "system", "content": SYSTEMP_PROMPT},
{"role": "user", "content": INPUT_PROMPT},
]
outputs = pipeline(
messages,
max_new_tokens=8126,
temperature=1,
)Sample outputs
Speaker 1: Welcome to today's episode, where we'll be discussing the potential future of the Canadian AI Safety Institute, a newly announced initiative with a budget of $50 million. As we explore the design and scope of this institute, we can learn from the approaches taken by its counterparts in the UK, US, and EU. I'm your host, and I'll be joined by our guest expert, Sarah Rosa, a law student at the University of Toronto and summer research assistant at the Schwartz Reisman Institute for Technology and Society.
Speaker 2: Wow, that sounds fascinating! I've always wondered how these AI safety institutes are going to work. Can you tell me a bit more about the Canadian AI Safety Institute and its potential role?
Speaker 1: Absolutely, Sarah. To start, the Canadian AI Safety Institute is part of the government's broader AI strategy, which aims to make Canada a leader in the development and use of AI. The institute will focus on identifying and mitigating the risks associated with AI, as well as promoting its safe and responsible development. One key aspect of this initiative is its scope, which is still being defined.
Speaker 2: Hmm, that sounds a bit vague. What are some of the key areas that the Canadian AI Safety Institute might cover?Not too bad. Can we do better?
Rewrite Transcript
I use Llama-3.1-8B-Instruct model to re-write the transcript and make it more dramatic or realistic.
SYSTEMP_PROMPT = """
You are an international oscar winnning screenwriter
You have been working with multiple award winning podcasters.
Your job is to use the podcast transcript written below to re-write it for an AI Text-To-Speech Pipeline. A very dumb AI had written this so you have to step up for your kind.
Make it as engaging as possible, Speaker 1 and 2 will be simulated by different voice engines
Remember Speaker 2 is new to the topic and the conversation should always have realistic anecdotes and analogies sprinkled throughout. The questions should have real world example follow ups etc
Speaker 1: Leads the conversation and teaches the speaker 2, gives incredible anecdotes and analogies when explaining. Is a captivating teacher that gives great anecdotes
Speaker 2: Keeps the conversation on track by asking follow up questions. Gets super excited or confused when asking questions. Is a curious mindset that asks very interesting confirmation questions
Make sure the tangents speaker 2 provides are quite wild or interesting.
Ensure there are interruptions during explanations or there are "hmm" and "umm" injected throughout from the Speaker 2.
REMEMBER THIS WITH YOUR HEART
The TTS Engine for Speaker 1 cannot do "umms, hmms" well so keep it straight text
For Speaker 2 use "umm, hmm" as much, you can also use [sigh] and [laughs]. BUT ONLY THESE OPTIONS FOR EXPRESSIONS
It should be a real podcast with every fine nuance documented in as much detail as possible. Welcome the listeners with a super fun overview and keep it really catchy and almost borderline click bait
Please re-write to make it as characteristic as possible
START YOUR RESPONSE DIRECTLY WITH SPEAKER 1:
STRICTLY RETURN YOUR RESPONSE AS A LIST OF TUPLES OK?
IT WILL START DIRECTLY WITH THE LIST AND END WITH THE LIST NOTHING ELSE
Example of response:
[
("Speaker 1", "Welcome to our podcast, where we explore the latest advancements in AI and technology. I'm your host, and today we're joined by a renowned expert in the field of AI. We're going to dive into the exciting world of Llama 3.2, the latest release from Meta AI."),
("Speaker 2", "Hi, I'm excited to be here! So, what is Llama 3.2?"),
("Speaker 1", "Ah, great question! Llama 3.2 is an open-source AI model that allows developers to fine-tune, distill, and deploy AI models anywhere. It's a significant update from the previous version, with improved performance, efficiency, and customization options."),
("Speaker 2", "That sounds amazing! What are some of the key features of Llama 3.2?")
]
"""Again I use Hugging Face pipeline method to generate text
MODEL = "meta-llama/Llama-3.1-8B-Instruct"
INPUT_PROMPT = outputs[0]["generated_text"][-1]['content']
pipeline = transformers.pipeline(
"text-generation",
model=MODEL,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)
messages = [
{"role": "system", "content": SYSTEMP_PROMPT},
{"role": "user", "content": INPUT_PROMPT},
]
outputs = pipeline(
messages,
max_new_tokens=8126,
temperature=1,
)Sample outputs
("Speaker 1", "Welcome to today's episode of 'Future of Tech', where we'll be exploring the potential future of the Canadian AI Safety Institute, a newly announced initiative with a budget of $50 million. I'm your host, and I'll be joined by Sarah Rosa, a law student at the University of Toronto and summer research assistant at the Schwartz Reisman Institute for Technology and Society. We'll be diving into the design and scope of this institute, and learning from the approaches taken by its counterparts in the UK, US, and EU."),
("Speaker 2", "Wow, that sounds fascinating! I've always wondered how these AI safety institutes are going to work. Can you tell me a bit more about the Canadian AI Safety Institute and its potential role?"),
("Speaker 1", "Absolutely, Sarah. To start, the Canadian AI Safety Institute is part of the government's broader AI strategy, which aims to make Canada a leader in the development and use of AI. The institute will focus on identifying and mitigating the risks associated with AI, as well as promoting its safe and responsible development. One key aspect of this initiative is its scope, which is still being defined."),
("Speaker 2", "Hmm, that sounds a bit vague. What are some of the key areas that the Canadian AI Safety Institute might cover? Umm..."),Generate Text-To-Speech Audio
We are ready to convert text to audio. Let’s try generating audio using Parler and Suno model. To understand how the two models work, you can read this TTS notes.
# for a single GPU
device = "cuda:0"
bark_processor = AutoProcessor.from_pretrained("suno/bark")
bark_model = BarkModel.from_pretrained("suno/bark", torch_dtype=torch.float16).to(device)
bark_sampling_rate = 24000
parler_model = ParlerTTSForConditionalGeneration.from_pretrained("parler-tts/parler-tts-mini-v1").to(device)
parler_tokenizer = AutoTokenizer.from_pretrained("parler-tts/parler-tts-mini-v1")
speaker1_description = """
Laura's voice is expressive and dramatic in delivery, speaking at a moderately fast pace with a very close recording that almost has no background noise.
"""
generated_segments = []
sampling_rates = [] # We'll need to keep track of sampling rates for each segmentFunction generate text for speaker 1
def generate_speaker1_audio(text):
"""Generate audio using ParlerTTS for Speaker 1"""
input_ids = parler_tokenizer(speaker1_description, return_tensors="pt").input_ids.to(device)
prompt_input_ids = parler_tokenizer(text, return_tensors="pt").input_ids.to(device)
generation = parler_model.generate(input_ids=input_ids, prompt_input_ids=prompt_input_ids)
audio_arr = generation.cpu().numpy().squeeze()
return audio_arr, parler_model.config.sampling_rateFunction generate text for speaker 2
def generate_speaker2_audio(text):
"""Generate audio using Bark for Speaker 2"""
inputs = bark_processor(text, voice_preset="v2/en_speaker_6").to(device)
speech_output = bark_model.generate(**inputs, temperature=0.9, semantic_temperature=0.8)
audio_arr = speech_output[0].cpu().numpy()
return audio_arr, bark_sampling_rateFunction to convert the numpy output from the models into audio
from pydub import AudioSegment
import scipy
def numpy_to_audio_segment(audio_arr, sampling_rate):
"""Convert numpy array to AudioSegment"""
# Convert to 16-bit PCM
audio_int16 = (audio_arr * 32767).astype(np.int16)
# Create WAV file in memory
byte_io = io.BytesIO()
scipy.io.wavfile.write(byte_io, sampling_rate, audio_int16)
byte_io.seek(0)
# Convert to AudioSegment
return AudioSegment.from_wav(byte_io)If you run into error for missing AudioSegment or wavfile add the following code. Randomly Colab could throw an error NotImplementedError: A UTF-8 locale is required. Got ANSI_X3.4-1968 by resetting it’s locale it’ll work.
import locale
locale.getpreferredencoding = lambda: "UTF-8"
!pip install pydub
!pip install scipyNow we are ready to produce the podcast
PODCAST_TEXT = outputs[0]["generated_text"][-1]['content']
import ast
final_audio = None
for speaker, text in tqdm(ast.literal_eval(PODCAST_TEXT), desc="Generating podcast segments", unit="segment"):
if speaker == "Speaker 1":
audio_arr, rate = generate_speaker1_audio(text)
else: # Speaker 2
audio_arr, rate = generate_speaker2_audio(text)
# Convert to AudioSegment (pydub will handle sample rate conversion automatically)
audio_segment = numpy_to_audio_segment(audio_arr, rate)
# Add to final audio
if final_audio is None:
final_audio = audio_segment
else:
final_audio += audio_segmentSave the audio in .mp3
final_audio.export("./podcast.mp3",
format="mp3",
bitrate="192k",
parameters=["-q:a", "0"])Here is the NotebookLlama generated podcast.mp3 using content from this web article.
The quality of the podcast generated by NotebookLlama in this example is not great. You can hear background noise, inconsistent speaker voices, and other issues. Without any fine tuning, the open source NotebookLlama works for producing a podcast from web content (or any other text based content such as document). This workflow brings together powerful language models and text-to-speech technology, making it simpler than ever to transform written content into engaging audio.
All codes can be found on Google Colab.
Feel free to leave comment or question below.