Previously I built a LLM chatbot with PDF documents, using the Retrieval Augmented Generation (RAG) technique. Traditional RAG leverages vector database and search retrieval methods, which measure the similarity or relatedness between different entities (such as words or phrases) based on their high-dimensional vector representations, typically the cosine similarity. For example, in a vector representation, the word “employee” may be more related to “employer” than “hired”, as it appears closer in the vector space.
One of the the problems with the vector database is that it ignores the structure and relationship of entities. We can manage this challenge by introducing Knowledge Graph, a data structure that organizes data as nodes and edges enhancing the contextuality of retrieved information.
A knowledge graph consists Subject-Predicate-Object triplets, where subjects/objects are represented by the nodes and predicates/relationships are represented by the edges. For example, in this triplet “employer – submit – claim”, “submit” is the predicate and indicates the relationship between “employer” and “claim”. By triplet representation, a knowledge graph database can make complex data search more accurate and efficient.
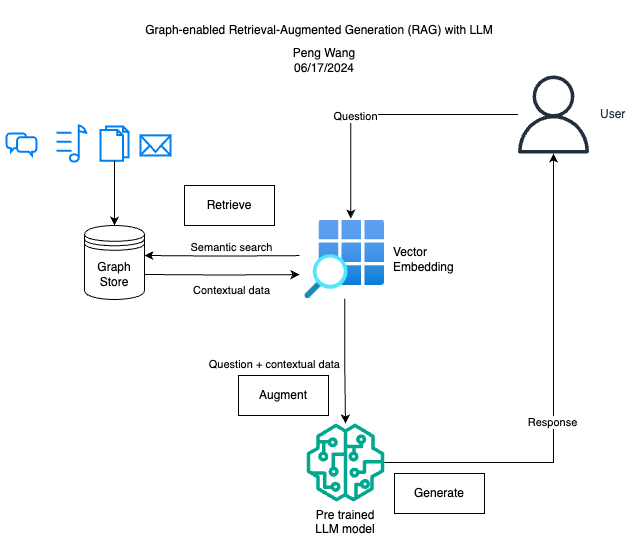
I adapted the pipeline from the previous RAG LLM experiment and made queries using the same PDF document. Instead of VectorStoreIndex, I used KnowledgeGraphIndex and GraphStore for extracting and storing knowledge graph. A knowledge graph index is constructed using the document. The include_embeddings=True parameter ensures that semantic embeddings of the nodes and edges are also included to enhance the search capabilities.
from llama_index.core.storage.storage_context import StorageContext
from llama_index.core import SimpleDirectoryReader, KnowledgeGraphIndex
from llama_index.core.graph_stores import SimpleGraphStore
graph_store = SimpleGraphStore()
storage_context = StorageContext.from_defaults(graph_store=graph_store)
index_graph = KnowledgeGraphIndex.from_documents(documents=documents,
max_triplets_per_chunk=3,
storage_context=storage_context,
embed_model=embed_model,
include_embeddings=True)
Here is a quick summary of the tech stack:
- LlamaIndex: orchestration framework for connecting custom data sources to LLMs
- Embedding: HuggingFaceEmbedding sentence-transformers/multi-qa-MiniLM-L6-cos-v1
- LLM: HuggingFaceLLM meta-llama/Llama-2-7b-chat-hf
- Knowledge graph database: KnowledgeGraphIndex and GraphStore
- Network visualization: PyVis
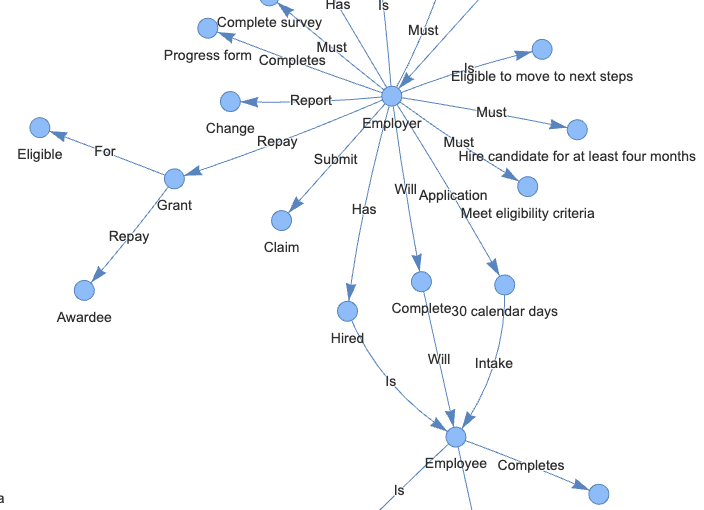
The graphs below are examples that are captured by the knowledge graph from texts in the provided document. They clearly show the relationships between different subjects and objects. The full zoomable knowledge graph can be found here.
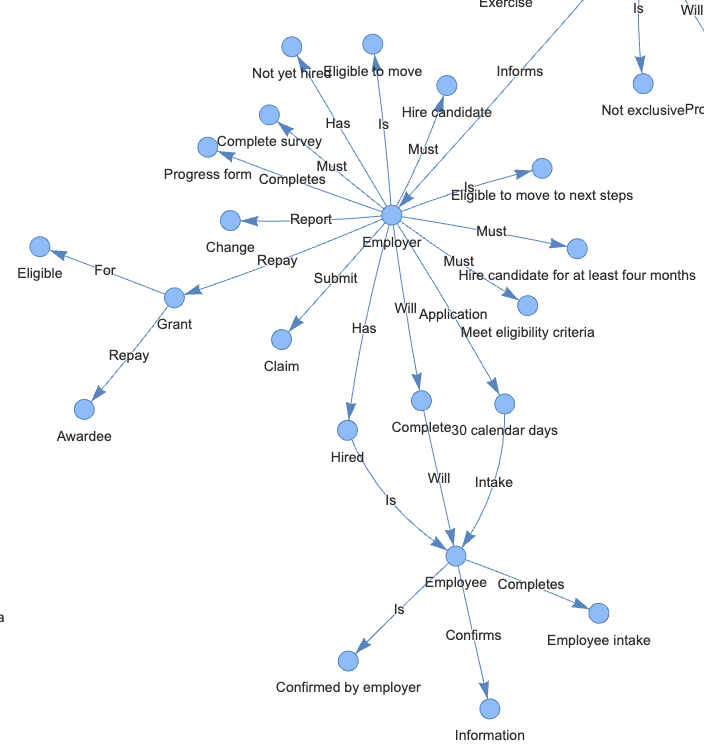
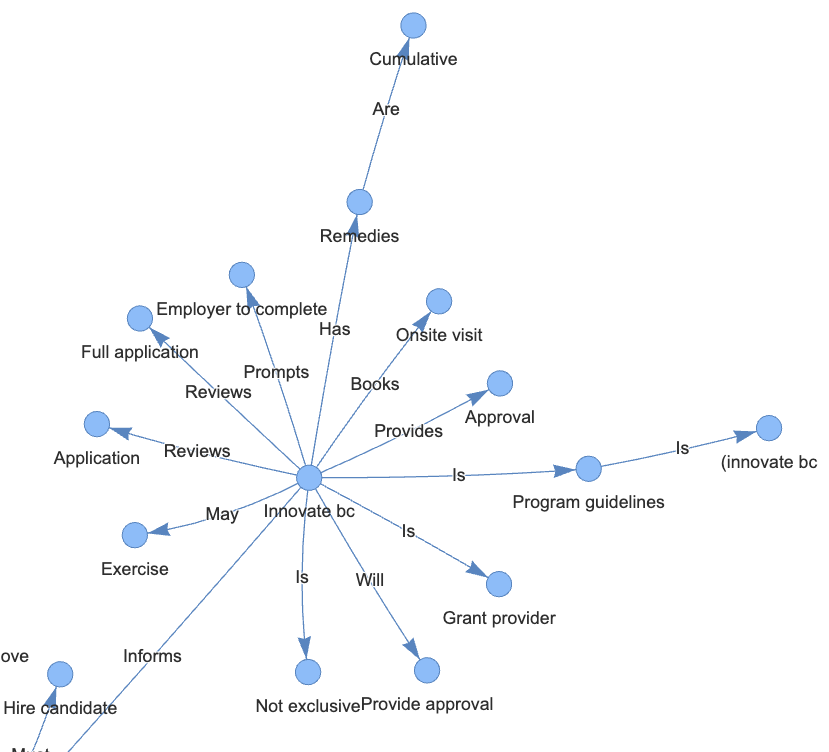
Future research would include:
- Build the knowledge graph and visualization using graph database such as Neo4j
- How to measure and compare the accuracy of Graph RAG vs Vector RAG
All codes can be found on Google Colab.
Feel free to leave comment or question below.