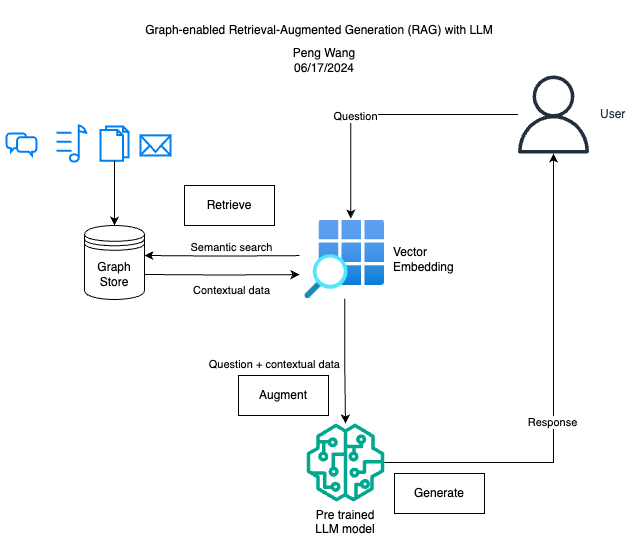
Previously I built a LLM chatbot with PDF documents, using the Retrieval Augmented Generation (RAG) technique. Traditional RAG leverages vector database and search retrieval methods, which measure the similarity or relatedness between different entities (such as words or phrases) based on their high-dimensional vector representations, typically the cosine similarity. For example, in a vector representation, the word “employee” may be more related to “employer” than “hired”, as it appears closer in the vector space.
One of the the problems with the vector database is that it ignores the structure and relationship of entities. We can manage this challenge by introducing Knowledge Graph, a data structure that organizes data as nodes and edges enhancing the contextuality of retrieved information.
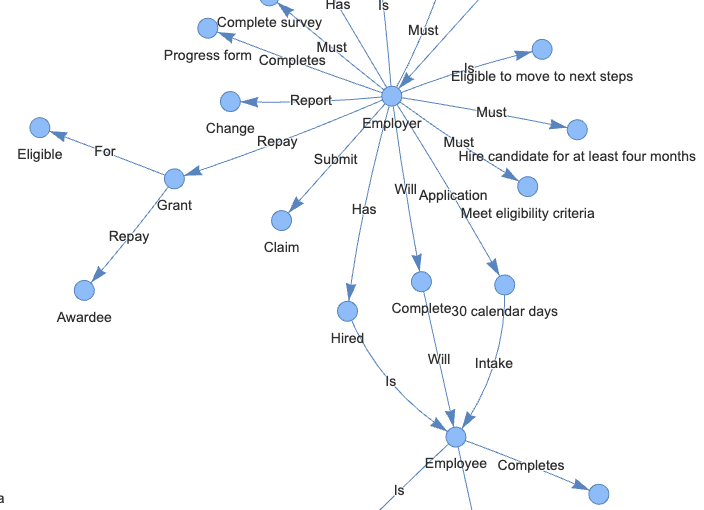
A knowledge graph consists Subject-Predicate-Object triplets, where subjects/objects are represented by the nodes and predicates/relationships are represented by the edges. For example, in this triplet “employer – submit – claim”, “submit” is the predicate and indicates the relationship between “employer” and “claim”. By triplet representation, a knowledge graph database can make complex data search more accurate and efficient.