
Have you applied for loans, grants, or financial assistance programs? Have you dedicated significant time to deciphering legal or contractual documents to understand regulations and rules? Are you looking to streamline the process of reviewing extensive requirement documents? Your solution is here. I have developed an LLM chatbot, supported by RAG, to provide prompt responses to user inquiries based on the content of provided PDF documents.
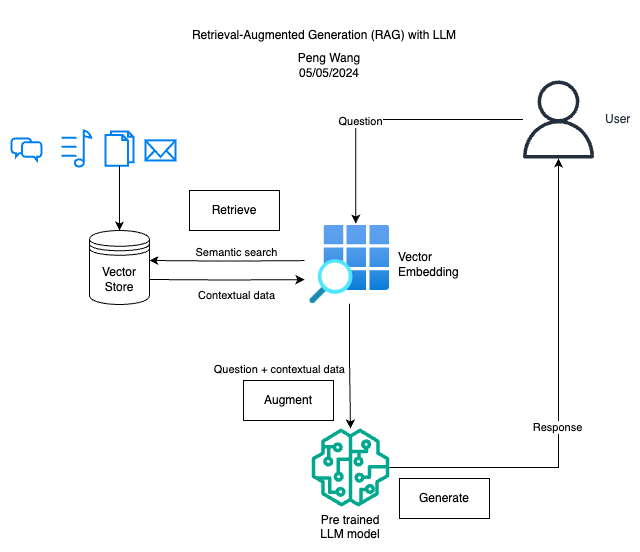
Retrieval Augmented Generation (RAG) involves enhancing Large Language Models (LLMs) with additional information from custom external data sources. This approach improves the LLM’s understanding by providing context from retrieved data or documents, enhancing its ability to respond to user queries with domain-specific knowledge.
- Retrieve: User queries are used to fetch relevant context from an external knowledge source. The queries are embedded into a vector space along with the additional context, allowing for a similarity search. The top k closest data objects from the vector database are then returned.
- Augment: The user query and retrieved additional context are combined into a prompt template.
- Generate: The retrieval-augmented prompt is then input into the LLM for final processing.
In my experiment, I utilized PDF documents as the external knowledge source. Users can ask questions or make queries based on the context provided in these documents. I employed the HuggingFace model sentence-transformers/multi-qa-MiniLM-L6-cos-v1 for vector embedding and the pre-trained LLM model meta-llama/Llama-2-7b-chat-hf for generating the final results.
I run the experiment using Google Colab, with A100 GPU. Here is the Colab notebook.
Pre Setup
The following Python libraries are needed to run the code:
- pypdf, python-dotenv
- transformers, einops, accelerate, langchain, bitsandbytes, sentence_transformers
- llama-index, llama-index-llms-huggingface, llama-index-embeddings-langchain
You will also need a Hugging Face access token
Retrieve
Load PDF Documents
Upload PDF documents to the root directory. Example PDF documents
documents = SimpleDirectoryReader(input_dir="/content/", required_exts=".pdf").load_data()Vector Embedding
HuggingFaceEmbeddings is a class in the LangChain library that provides a wrapper around Hugging Face’s sentence transformer models for generating text embeddings. It allows you to use any sentence embedding model available on Hugging Face for tasks like semantic search, document clustering, and question answering. For more details about HuggingFaceEmbeddings, you can read Local Embeddings with HuggingFace
I tried three HF sentence transformer models multi-qa-MiniLM-L6-cos-v1,all-MiniLM-L6-v2, all-mpnet-base-v2. all-MiniLM-L6-v2 and all-mpnet-base-v2 did not perform well and answers often have hallucination i.e. non factual incorrect answers. multi-qa-MiniLM-L6-cos-v1 is more suitable for Q&A conversation.
EMBEDDING_MODEL_NAME = "sentence-transformers/multi-qa-MiniLM-L6-cos-v1"
embed_model = HuggingFaceEmbeddings(model_name=EMBEDDING_MODEL_NAME)
Vector Store is a type of index that stores data as vector embeddings. These vector embeddings are numerical representations of the data that capture their semantic meaning. This allows for efficient similarity searches, where the most similar items to a given query are retrieved.
index = VectorStoreIndex.from_documents(documents, embed_model = embed_model)
Augment
Set up prompts
from llama_index.core import PromptTemplate
system_prompt = """<|SYSTEM|># You are an AI-enabled admin assistant.
Your goal is to answer questions accurately using only the context provided.
"""
# This will wrap the default prompts that are internal to llama-index
query_wrapper_prompt = PromptTemplate("<|USER|>{query_str}<|ASSISTANT|>")
LLM_MODEL_NAME = "meta-llama/Llama-2-7b-chat-hf"
Import models from HuggingFace directly
llm = HuggingFaceLLM(
context_window=4096,
max_new_tokens=512,
generate_kwargs={"temperature": 0.1, "do_sample": False},
system_prompt=system_prompt,
query_wrapper_prompt=query_wrapper_prompt,
tokenizer_name=LLM_MODEL_NAME,
model_name=LLM_MODEL_NAME,
device_map="auto",
# uncomment this if using CUDA to reduce memory usage
model_kwargs={"torch_dtype": torch.float16 , "load_in_8bit":True}
)
Introduced in LlamaIndex v0.10.0, there is a new global Settings object intended to replace the old ServiceContext configuration.
The new Settings object is a global settings, with parameters that are lazily instantiated. Attributes like the LLM or embedding model are only loaded when they are actually required by an underlying module. For more, you can read Migrating from ServiceContext to Settings
from llama_index.core import Settings
Settings.embed_model = embed_model
Settings.llm = llm
Settings.chunk_size = 1024
Generate
Initialize the Query Engine
query_engine = index.as_query_engine(llm=llm, similarity_top_k=5)
Generate contextual results using retrieval-augmented prompt
done = False
while not done:
print("*"*30)
question = input("Enter your question: ")
response = query_engine.query(question)
print(response)
done = input("End the chat? (y/n): ") == "y"
Summary
I have implemented a RAG pipeline for building a personalized chatbot. The chatbot utilizes the provided external PDF documents as knowledge base and can provide tailored answers using the sentence-transformers/ embedding model and the pre-trained LLM model multi-qa-MiniLM-L6-cos-v1meta-llama/Llama-2-7b-chat-hf
All codes can be found on Google Colab.
Feel free to leave comment or question below.