
Predicting someone’s demographic attributes based on limited amount of information available is always a hot topic. It is common to use people’s name, ethnicity, location, and pictures for training models that can tell gender. Can you actually guess someone’s gender only based on what they share on Twitter? We will explore this using NLP techniques in this article.
At the end we conclude that it is quite a challenge to predict someone’s gender only using a single tweet. However, by combining prediction results from many tweets of the same person (similar to ensemble techniques like bagging), we may reach much better performance.
Ethical or Non Ethical
Is predicting someone’s ethnicity or gender an ethical practice? Should we trust the results or would it introduce unnecessary bias to the model?
The answer is it depends. It is probably inappropriate to develop a statistical model using gender, ethnicity and age as features to determine the likelihood of employee promotion. In such a case, the historical data used for training is probably highly imbalanced in gender and ethnicity, which will lead to biased predictions. More importantly, gender, ethnicity and age add no value to the selection criteria.
On the other hand, sometimes if a model can tell someone’s gender or other demographic information with some reasonably good accuracy, it would help greatly on understanding their customers and driving business decisions. Imagine a fashion company is launching a social media marketing campaign on Twitter and they specifically want to target female customers. If a model that can tell gender of Twitter accounts using tweets, profile, and images, it will save the business tremendous amount of costs and delivering more effective message to the right group of audience. Even though the prediction accuracy is not great, it is still much better than knowing nothing about the audience and making random guesses.
Data Gathering
We manually collected a list of 37 Twitter accounts from Wiki list of most-followed Twitter accounts, and labeled gender. Only binary gender is considered in this study, and that is female (0) and male (1). Here are some examples:

Then, we scraped their recent tweets and gathered 23,454 shared tweets. These are all original tweets and no retweet.
Text Pre-processing
Text pre-processing is needed for transferring text from human language to machine-readable format for further processing. Here are the pre-processing steps on the Tweets:
- Convert all words to lowercase
- Remove non-alphabet characters
- Remove short word (length less than 3)
- Tokenization: breaking sentences into words
- Part-of-speech (POS) tagging: process of classifying words into their grammatical category, in order to understand their roles in a sentence, e.g. verbs, nouns, adjectives, etc. POS tagging provides grammar context for lemmatization.
- Lemmatization: converting a word to its base form e.g.
car, cars, car’stocar - Remove common English words e.g. a, the, of, etc., and remove common words that add very little value to our analysis, e.g. com, twitter, pic, etc.
import nltk
from nltk.corpus import stopwords, wordnet
from nltk.stem import WordNetLemmatizer
additional_stop_words=['twitter','com','pic']
def get_wordnet_pos(word):
"""
Map POS tag to first character lemmatize() accepts
"""
tag = nltk.pos_tag([word])[0][1][0].upper()
tag_dict = {"J": wordnet.ADJ,
"N": wordnet.NOUN,
"V": wordnet.VERB,
"R": wordnet.ADV}
return tag_dict.get(tag, wordnet.NOUN)
def text_cleanup(text):
'''
Text pre-processing
return tokenized list of cleaned words
'''
# Convert to lowercase
text_clean = text.lower()
# Remove non-alphabet
text_clean = re.sub(r'[^a-zA-Z]|(\w+:\/\/\S+)',' ', text_clean).split()
# Remove short words (length < 3)
text_clean = [w for w in text_clean if len(w)>2]
# Lemmatize text with the appropriate POS tag
lemmatizer = WordNetLemmatizer()
text_clean = [lemmatizer.lemmatize(w, get_wordnet_pos(w)) for w in text_clean]
# Filter out stop words in English
stops = set(stopwords.words('english')).union(additional_stop_words)
text_clean = ' '.join([w for w in text_clean if w not in stops])
return text_clean
# Preprocess tweets
all_tweets_df['token'] = [text_cleanup(x) for x in all_tweets_df['text']] We only take processed tweets that have more than 20 characters because a tweet is too short and has little meaning.
tweets = all_tweets_df[all_tweets_df['token'].apply(len)>20]After pre-processing, 19,663 tweets remain in training data set and it seems female and male are well balanced.
>>tweets.gender.value_counts(normalize=True, sort=False)
female 0.496313
male 0.503687
Name: gender, dtype: float64Example tweets after pre-processing:

Training Logistic Regression Using TF-IDF Features
TF-IDF Features
We use TF-IDF (term frequency-inverse document frequency) as features to feed to the model.
TF-IDF calculates TF x IDF as the weight for each word in the dictionary, representing how frequent this word is in the text/tweet multiplied by how unique the word is across all texts/tweets. The TF-IDF weight highlights the words that are distinct (relevant information) in a tweet.
text_transformer = TfidfVectorizer()
X = text_transformer.fit_transform(tweets[‘token’])
y = tweets[‘gender’]Model Training
We split our training data and hold 20% for validation.
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, stratify=y, random_state=39)The basic Logistic Regression algorithm was used as the classifier.
logreg = LogisticRegression()
logreg.fit(X_train, y_train)LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, l1_ratio=None, max_iter=100,
multi_class='auto', n_jobs=None, penalty='l2',
random_state=None, solver='lbfgs', tol=0.0001, verbose=0,
warm_start=False)By applying the model on the validation data set, we can check the model performance.
y_val_pred = logreg.predict(X_val)
Here is the confusion matrix and F1 score which are commonly used for evaluation classification accuracy. F1 score is 0.7699 (1.0 is perfect precision and recall). Not bad.
>>confusion_matrix(y_val, y_val_pred)
array([[1539, 413],
[ 492, 1489]], dtype=int64)
>>f1_score(y_val, y_val_pred, average=’micro’)
0.7698957538774472Predicting Gender On Test Data
We gathered the tweets of the following four Twitter accounts for testing. None of them was included in our training data set.
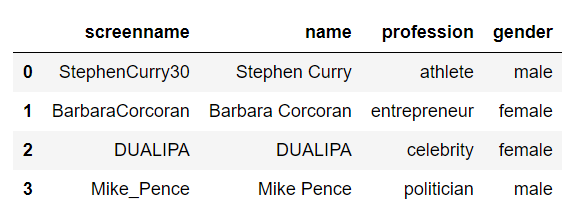
After the same pre-processing steps, we had 208 test tweets. Female and male ratio is again balanced.
female 0.504808
male 0.495192We built TF-IDF features for test data and applied the training Logistic Regression model. Here is the performance on test data. F1 score is 0.5913. It is not a great number but 10% better than a 50–50 random guess.
>>confusion_matrix(test_tweets.gender, pred)
array([[58, 47],
[38, 65]], dtype=int64)
>>f1_score(test_tweets.gender, pred, average='micro')
0.5913461538461539
Let’s take a look at some examples.
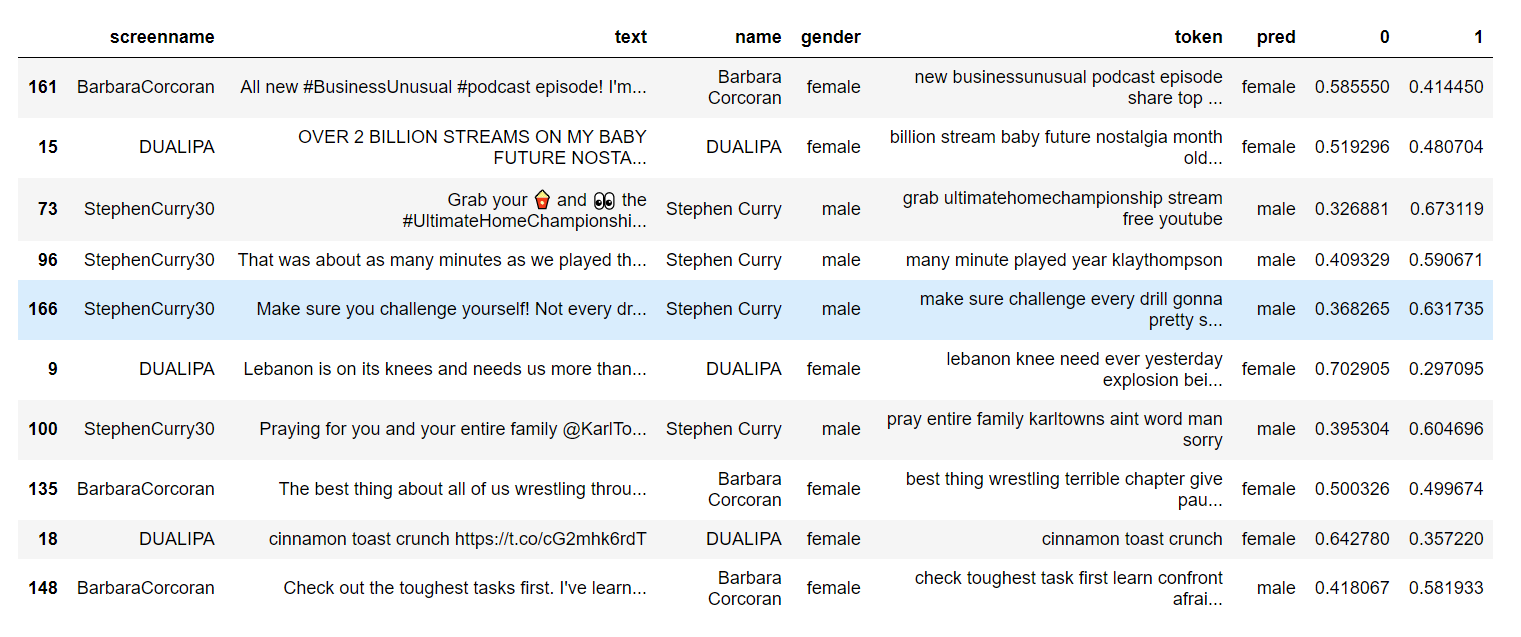
All new #BusinessUnusual #podcast episode! I’m sharing my top tip to prepare for fall & answering questions you cal… https://t.co/vBXPbCDkA6
It is from Barbara Corcoran (female) and our model said female too.
OVER 2 BILLION STREAMS ON MY BABY FUTURE NOSTALGIA!! ! Only 4 months old and she’s doin her lil thaaaang! I’m so pr… https://t.co/vZL9KSClJY
It is from DUALIPA (female) and our model said female too.
Check out the toughest tasks first. I’ve learned to confront what I’m afraid to do and just get it out of the way.… https://t.co/0zvFir96TM
It is from Barbara Corcoran (female) and our model said male. Incorrect.
If we combine all predictions for each test Twitter account and make a gender prediction of the account by the majority vote, here is the result. 3 out of 4 are correct! Not bad at all.

Closing Notes
In this study, we applied some NLP techniques (i.e. text pre-processing and TF-IDF features) and built a predictive model that can tell someone’s gender only based on their tweets. Prediction accuracy on a single tweet is 0.59, slightly better than a 50–50 random guess. By combining more tweets from the same person and leveraging majority vote, we were able to achieve much better result.
A social marketing professional can use this information to select the target female/male audience and launch a more effective marketing campaign on Twitter.
In the future works, we can try the following to improve prediction accuracy:
- Introduce more tweets for training
- Instead of basic Logistic Regression, try other models such as XGBoost
- Add other features to the data set such as user name, profile bio, etc
All codes can be found on GitHub.